AI & Agent Evaluation
1,866total visitsadmin
ResearchGate — From Holistic Evaluation to Structured Criteria: A Survey of Rubrics Across the Evolving LLM Landscape
preprint · source date 2026-05-31 · added 2026-06-08 21:48:13 · updated 2026-06-08 22:05:14 · Open original blog
Problems / challenges / motivations
- As LLMs move from task-specific systems toward open-ended agents, one scalar score is often too opaque. A medical answer, deep-research report, tool-using trajectory, or multimodal output may need separate checks for factuality, completeness, reasoning soundness, evidence use, safety, format compliance, and practical utility.
- The paper argues that rubrics keep reappearing across evaluation, reinforcement learning, and safety alignment because they solve the same interface problem: they turn broad human expectations into explicit criteria that models, judges, trainers, and auditors can act on.
- Holistic evaluation is useful for quick ranking, but it hides why a response failed and gives weak learning signal. Structured criteria make evaluation diagnostic: the score can say which dimension failed, whether the failure is local or global, and what should be improved.
Key ideas
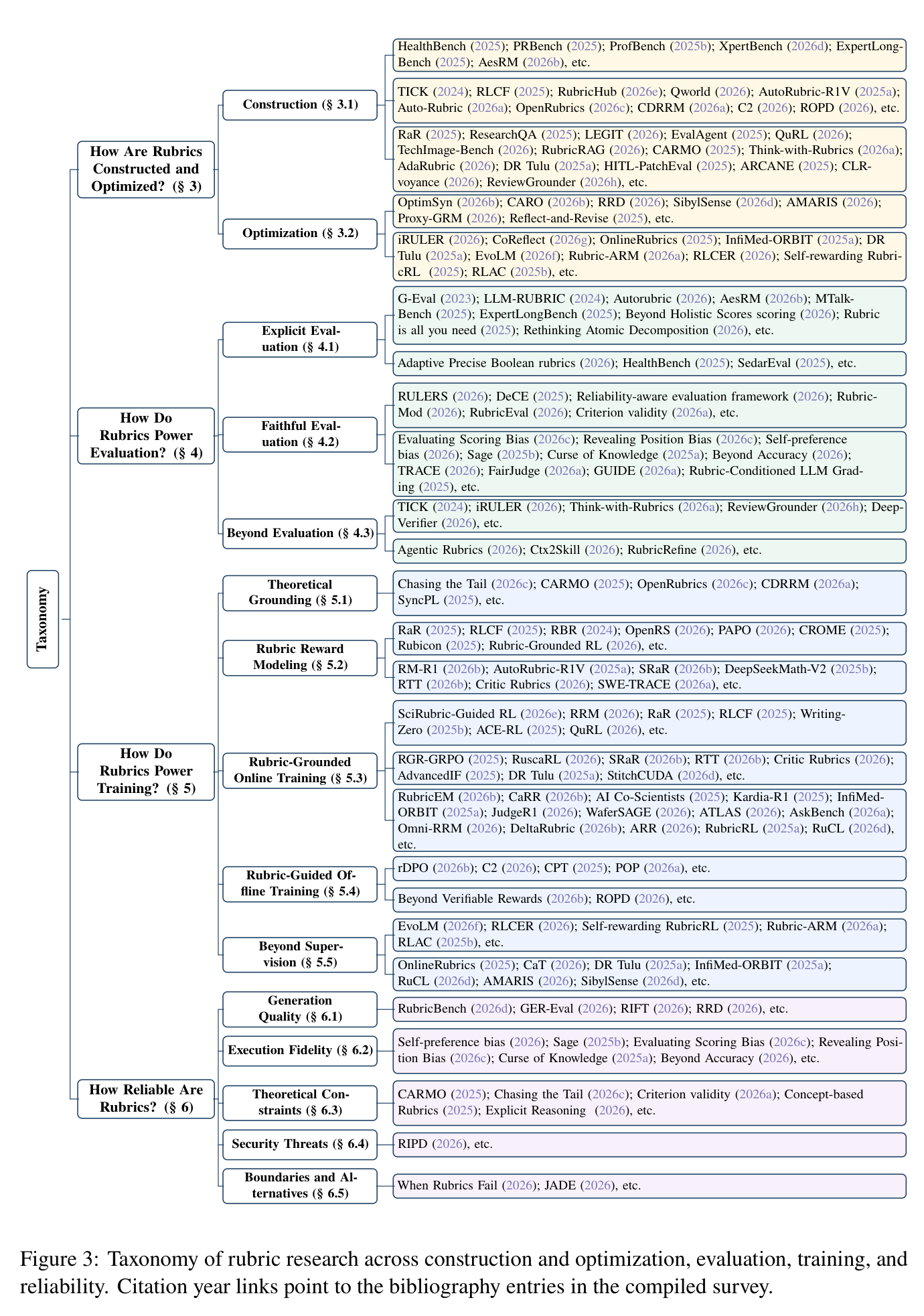
- The authors define rubrics as explicit sets of criteria that transform complex quality judgments into structured and actionable standards. They organize rubric forms by structure and content, then connect rubric evolution to LLM paradigm shifts: emergence, alignment, enrichment, reinforcement, and co-evolution.
- Rubrics are treated as a lifecycle, not just a judge prompt. The survey covers construction and optimization, evaluation, training, reliability, applications, and future directions.
- Construction methods include human expert construction, automated LLM construction, and human-in-the-loop construction. Optimization can be passive, such as verification and de-duplication, or active, where rubrics evolve from model behavior and failures.
- For evaluation, rubrics decompose holistic scores into dimensions and discrete formats such as Likert scales, Boolean checks, checklists, or criterion-level judgements. They also support test-time scaling through iterative self-refinement and parallel path selection.
- For training, rubrics can become dense feedback signals. Instead of a single scalar reward, rubric rewards can provide per-dimension or process-level feedback, helping models learn what to improve and supporting RL in tasks where final answers are hard to verify.
- The reliability section is important: rubrics can be badly generated, inconsistently executed, theoretically limited, or weaponized through reward hacking and adversarial criteria. The paper explicitly treats rubric safety and rubric failure modes as first-class issues.
Why it matters for evals
- This paper is directly relevant to LLM-as-judge and agent evaluation because it explains why evaluator prompts should expose criteria, not just return a score. Public benchmark results are more interpretable when the rubric, aggregation method, examples, and known gaps are visible.
- For agent evals, rubrics should cover both final outputs and intermediate trajectories: evidence gathering, tool choice, recovery from mistakes, policy compliance, reasoning steps, and whether the final answer follows from collected evidence.
- Rubrics improve auditability, but they also introduce a new attack surface. If the rubric becomes the reward, models may optimize for visible checklist items while missing unstated user value. Eval designers should test for rubric gaming, calibrate rubric judges against humans, and revise rubrics using real failures.
- The practical pattern is to move from “score this answer” to “state the criteria, judge each criterion, expose uncertainty, and preserve the evidence.” That makes evaluation more diagnostic, easier to debug, and more useful for model and harness improvement.
Comments
No comments yet.