AI & Agent Evaluation
1,865total visitsadmin
OpenAI Developers — Run long horizon tasks with Codex
developer blog · source date 2026-02-23 · added 2026-05-18 23:09:08 · updated 2026-05-30 17:20:13 · Open original blog
Problems / challenges / motivations
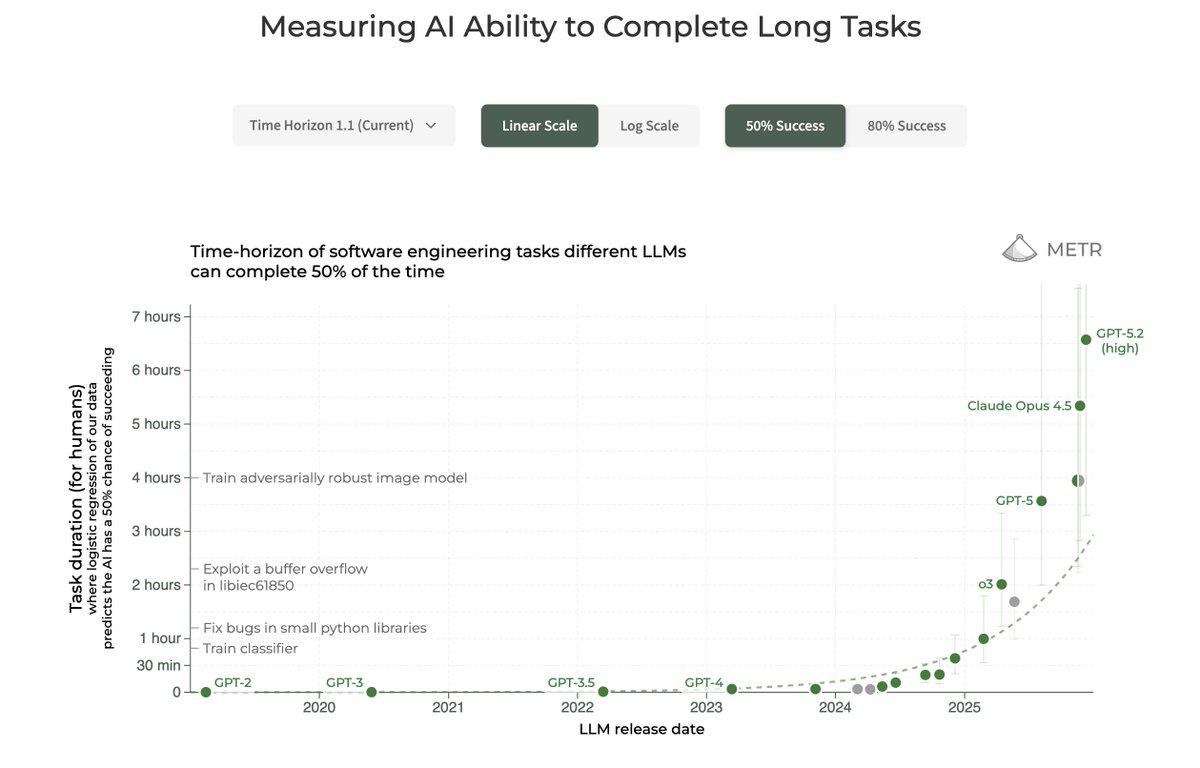
- OpenAI's developer post frames long-horizon reliability as a major shift for coding agents: real work requires maintaining intent across extended tasks, not just solving isolated snippets.
- Longer tasks create failure modes that short benchmarks miss: requirement drift, context loss, weak recovery, unreviewable changes, and inefficient tool use.
- The usefulness of a coding agent depends on workflow design as well as model capability: setup, project context, summaries, token use, and human review all affect outcomes.
Key ideas
- The article connects improved autonomous coding reliability to GPT-5-Codex and later model/platform updates.
- It emphasizes product workflow: giving the agent the right task context, preserving session state, summarizing progress, and keeping outputs reviewable.
- Long-horizon evals should ask whether the agent preserves requirements, recovers from errors, avoids drift, and completes realistic multi-step engineering work.
- Human review remains part of the loop because successful completion should include code quality, safety, and maintainability, not only task closure.
Why it matters for evals
- This is a useful companion to coding-agent benchmarks because it points from single-shot tests toward realistic engineering workflows.
- The eval target becomes successful, reviewable completion of multi-step work under human supervision.
- The reusable lesson is to measure duration, context management, observability, recovery, and reviewability alongside pass/fail correctness.
Comments