engineering blog · source date 2026-01-09 · added 2026-05-18 02:01:48 · updated 2026-07-26 18:58:13 · Open original blog
Deep dive — Anthropic: Demystifying evals for AI agents
Source: Anthropic Engineering, published 2026-01-09. Original: https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
Why this matters
Anthropic's core claim is simple but important: evaluating an agent is not the same as evaluating a chat response. Agents act over many turns, use tools, mutate external state, and can fail in ways that are invisible if you only grade the final message.
The practical implication: a good agent eval should grade the task outcome and the environment state, then use transcript review to understand why the result happened.

1. Agent evals have more moving parts than prompt evals
A simple LLM eval is usually: prompt → model response → grader. That works when the target behavior is a single answer.
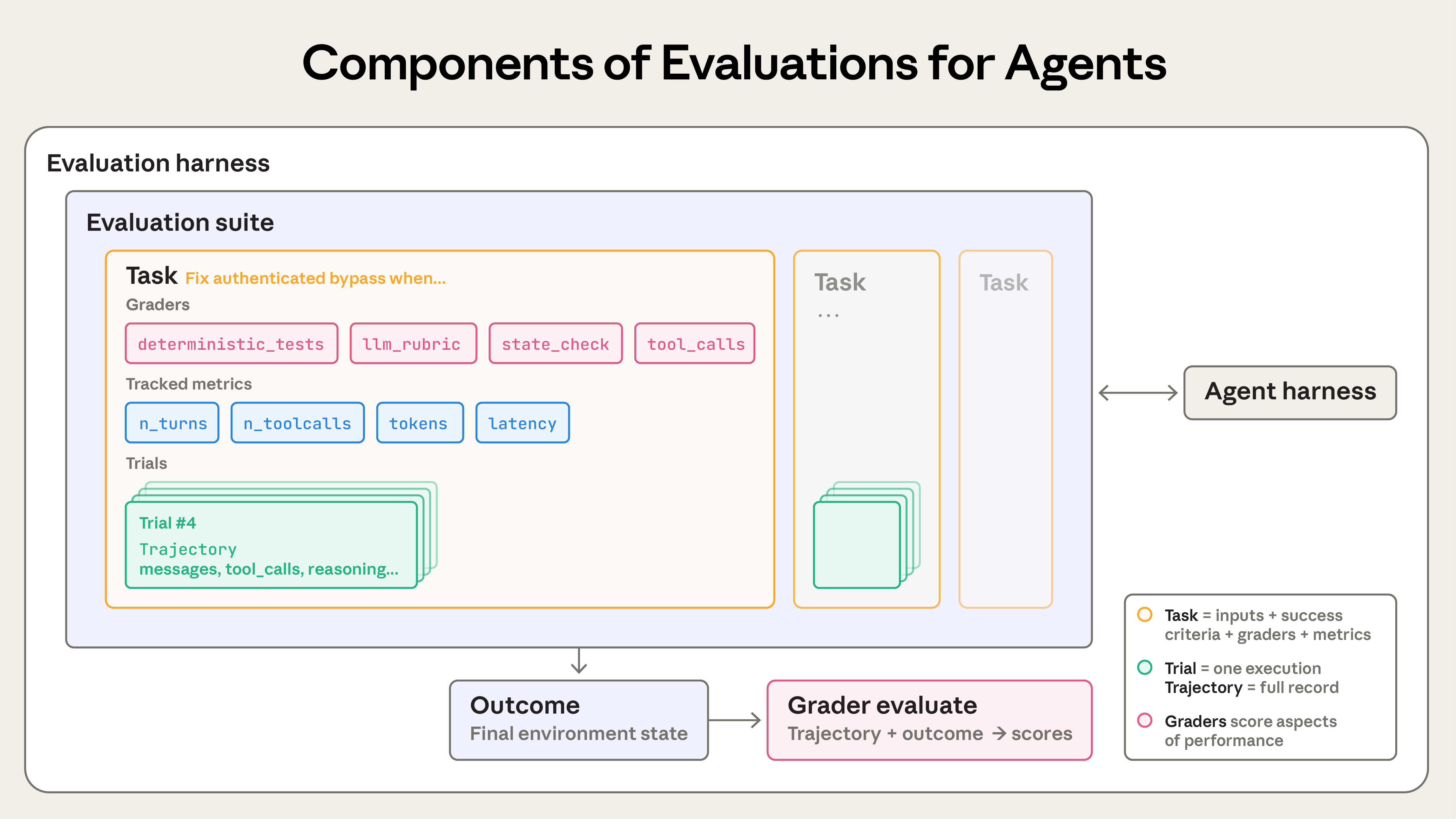
An agent eval has more structure:
- task: the problem and success criteria
- trial: one stochastic attempt at the task
- agent harness: the scaffold that runs the loop and tool calls
- eval harness: infrastructure that runs, records, grades, and aggregates trials
- transcript / trace: messages, tool calls, reasoning, observations, errors
- outcome: the final state of the world after the agent acted
- grader: deterministic, model-based, or human judgment over output, state, or trace
- suite: a collection of related tasks
The most useful distinction is transcript vs outcome. A flight agent can say “your flight is booked” while the database shows no reservation. For agent products, the database state is usually more important than the final sentence.
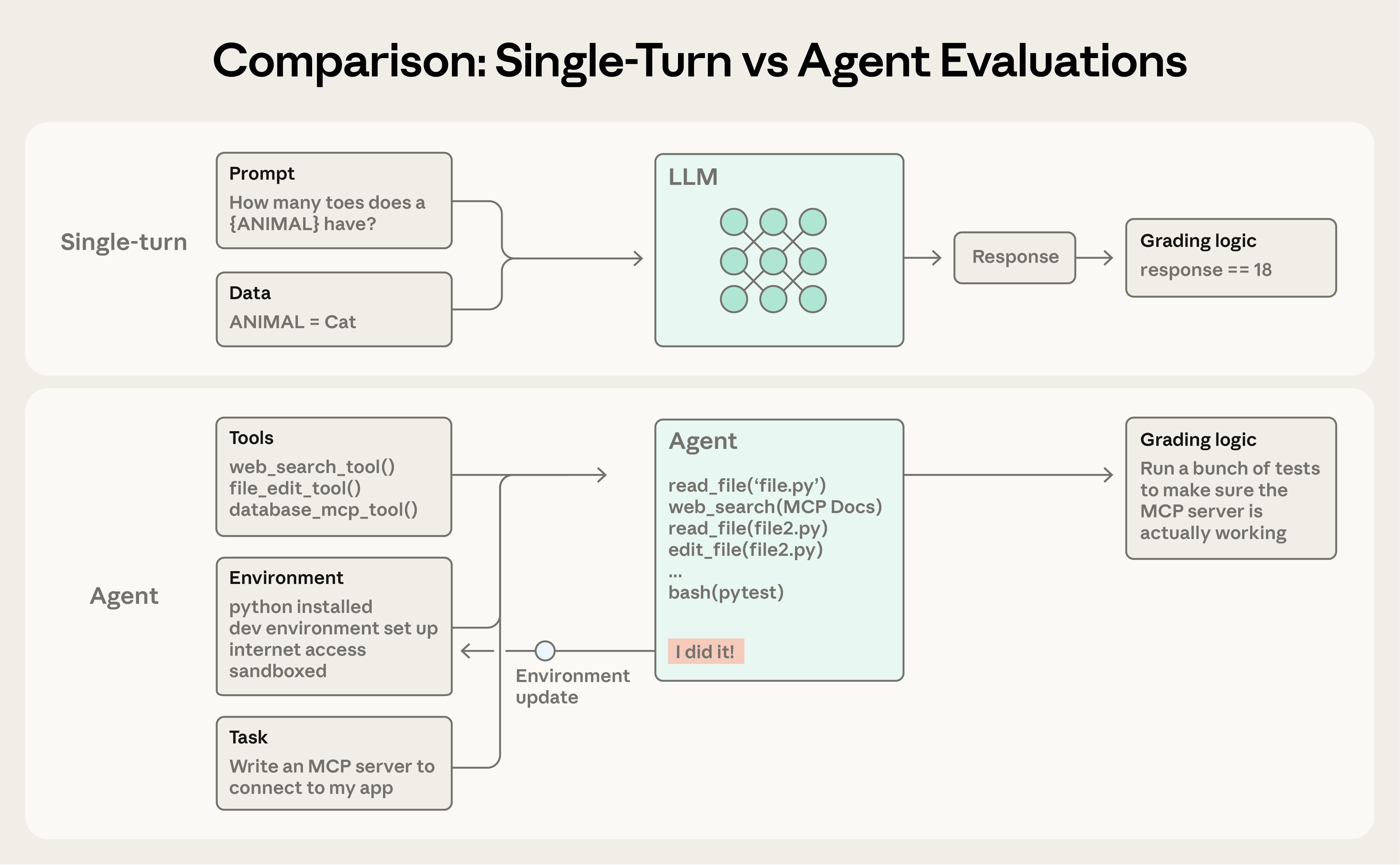
2. The right grading target is usually the outcome, not the text
Anthropic's strongest engineering advice is to prefer outcome/state checks wherever possible. Examples:
- coding agent: tests pass, files changed correctly, no unrelated damage
- customer support agent: refund record exists, escalation status is correct
- browser agent: target page state changed as requested
- data agent: query result and side effects match expectations
Final-answer checks are still useful, but they are weaker for agents because agents can hallucinate completion or solve the task through an unexpected path.
Judgment: this is the difference between a demo eval and a production eval. Demo evals often ask “did the answer sound right?” Production evals ask “did the system do the job safely and correctly?”
3. Use multiple grader types because each fails differently
Deterministic graders are best when the desired state is exactly checkable. They are fast, stable, cheap, and regression-test friendly. But they can reject valid creative solutions if the test is too narrow.
Model-based graders help with open-ended outputs, qualitative rubrics, and transcript triage. But they need calibration because judge models can drift, be biased, or reward plausible but wrong reasoning.
Human graders are expensive but important for subjective quality and for calibrating LLM judges.
Practical pattern:
- use deterministic checks for hard correctness and state
- use LLM judges for qualitative dimensions and open-ended traces
- periodically sample human review to calibrate both
- read transcripts when aggregate numbers move
4. Non-determinism means one run is not enough
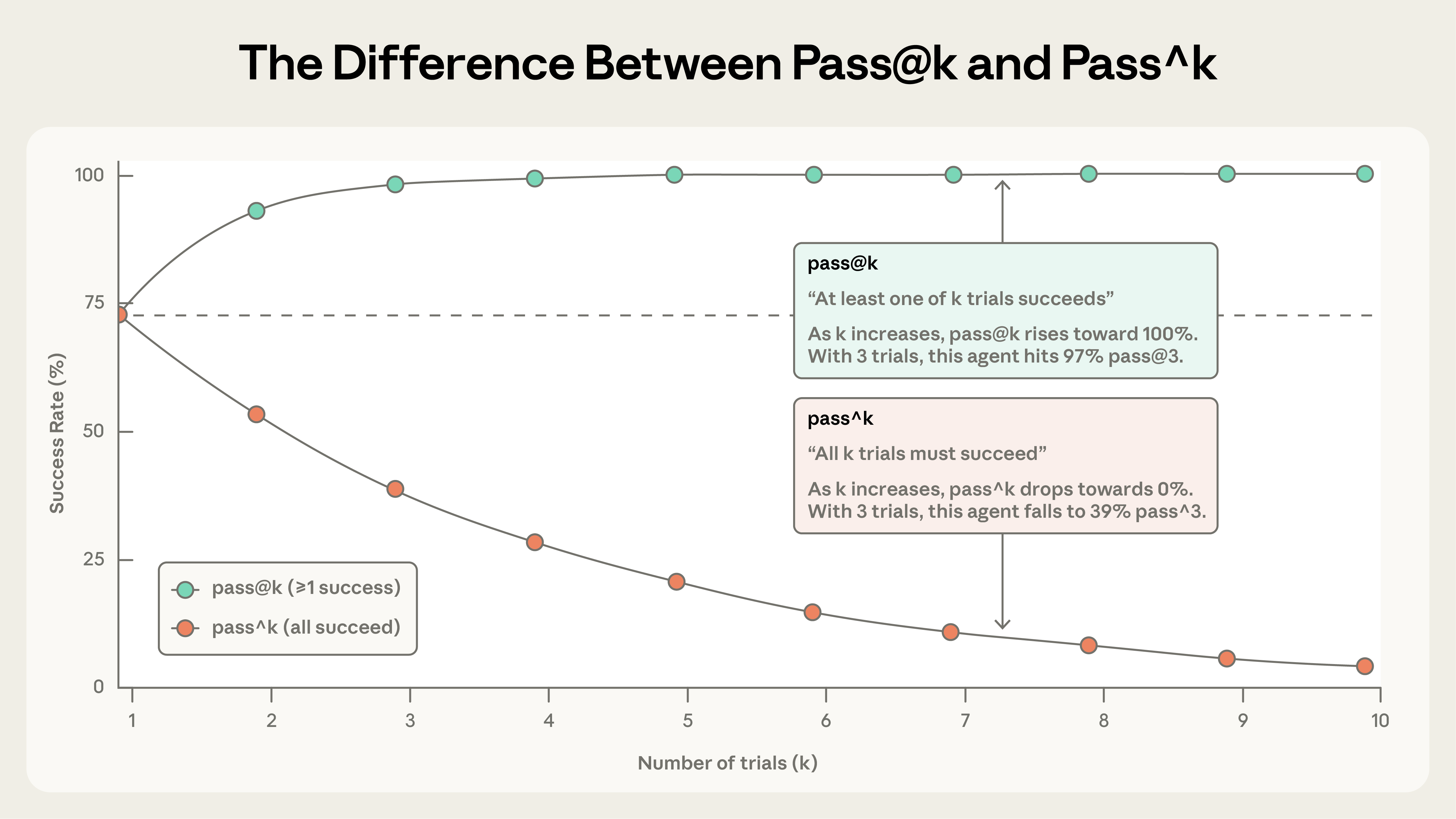
Agent results vary. The article highlights pass@k and pass^k:
- pass@k: probability that at least one of k trials succeeds
- pass^k: probability that all k trials succeed
These metrics answer different product questions. pass@k is useful when one successful attempt is enough, such as a research assistant where retries are acceptable. pass^k is stricter and matters for customer-facing agents where consistency is part of the product.
Example from the article: with a 75% per-trial success rate and 3 trials, pass^3 is 0.75³ ≈ 42%. A model can look capable but still be unreliable.
5. Split capability evals from regression evals
Capability evals ask: “Can the agent do this kind of task yet?” They should include hard tasks and should not all be near 100%. Low pass rates are useful because they expose future model improvements.
Regression evals ask: “Did we break behavior that used to work?” They should be stable, fast enough to run often, and tied to real product failures or important user journeys.
This distinction prevents a common mistake: turning every eval into a release gate. Some evals are for learning; others are for blocking bad releases.
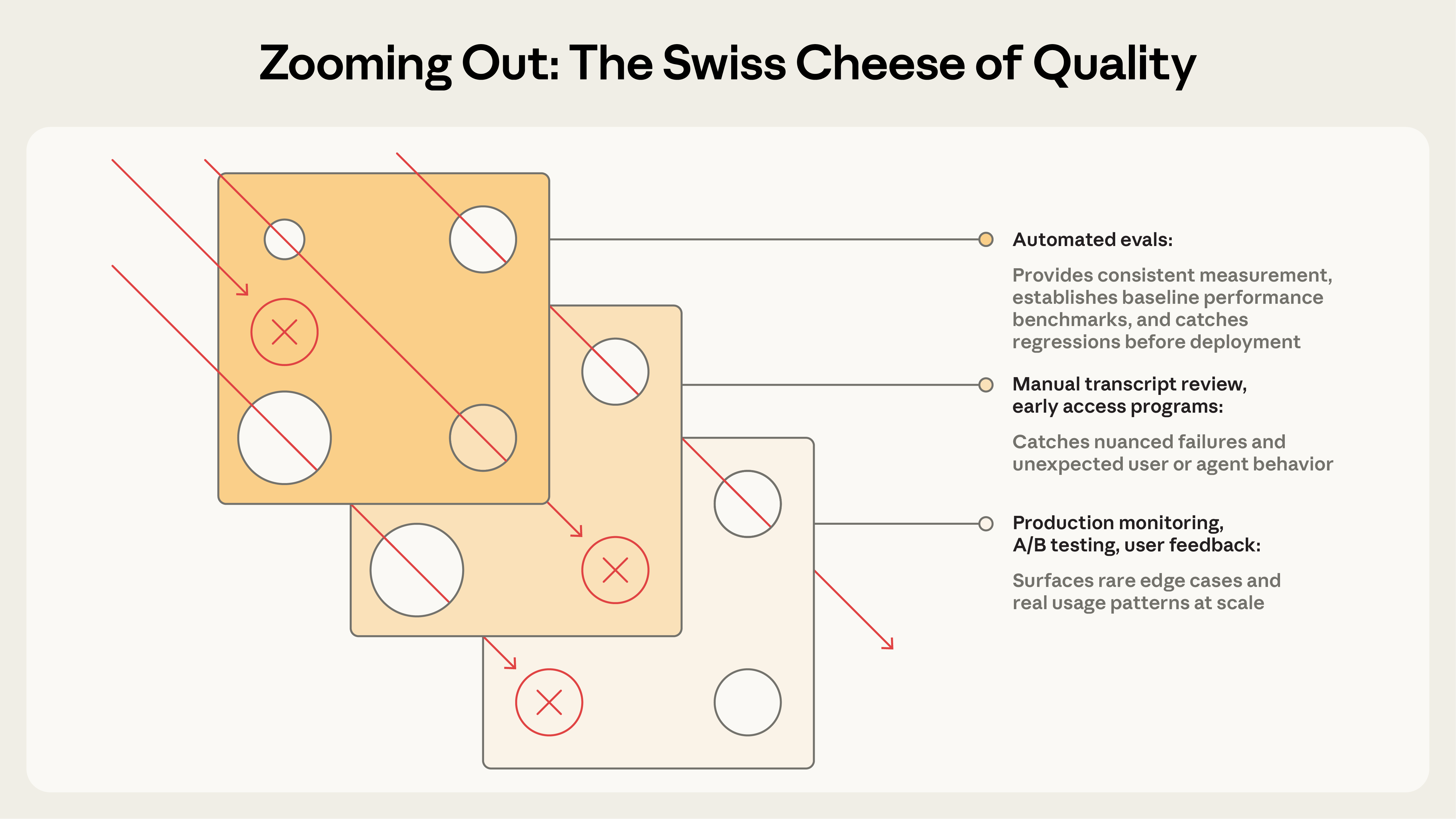
6. Evals are one layer, not the whole safety net
Anthropic argues for a layered view: automated evals, production monitoring, A/B tests, user feedback, transcript review, and human studies each catch different failure modes.
This is similar to the Swiss cheese model: every layer has holes, but stacked layers reduce the chance that a failure reaches users unnoticed.
What I would reuse from this article
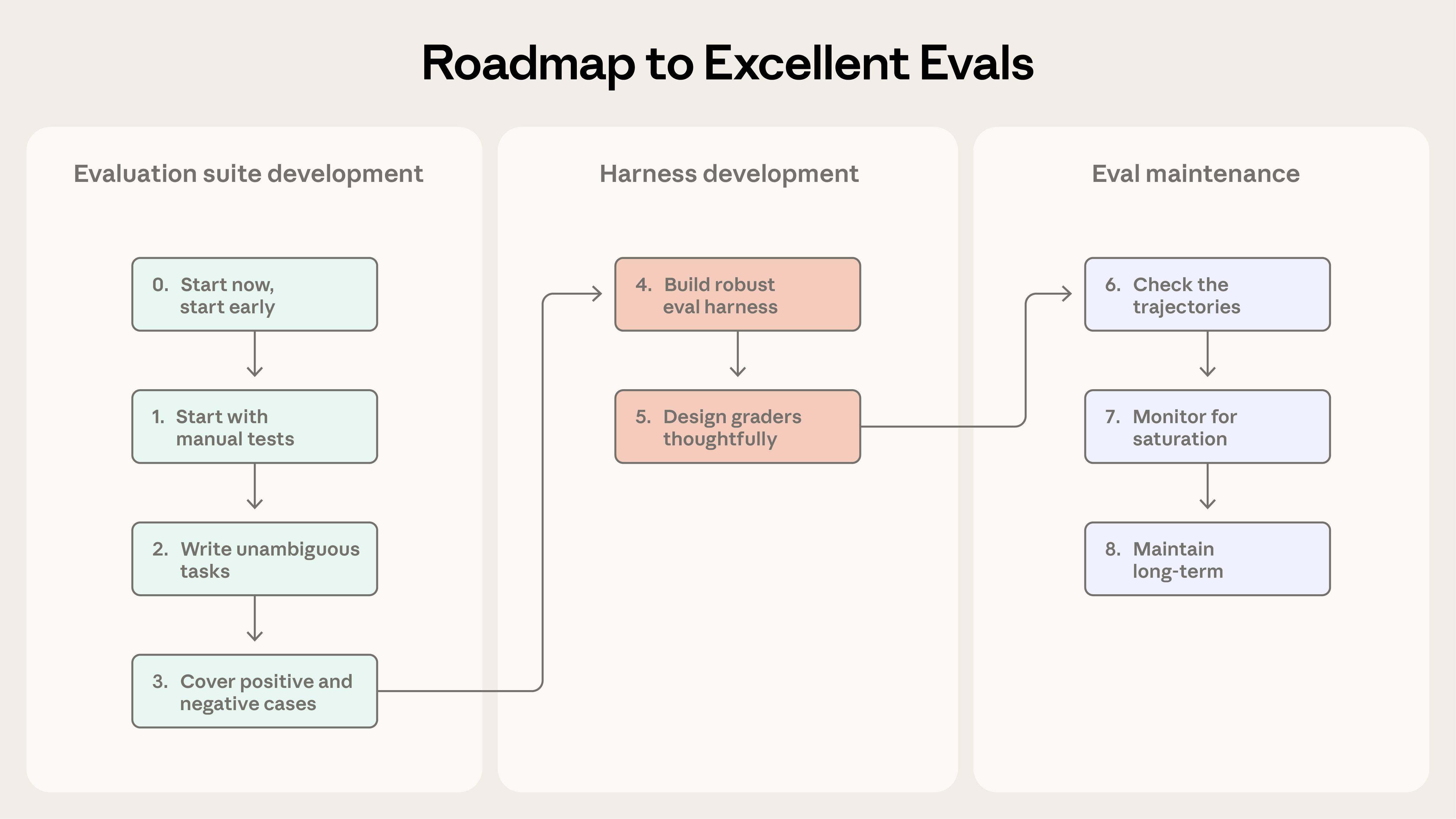
For any agent project, I would turn this into a checklist:
1. Define the task in terms of user-visible success. 2. Make the environment resettable and isolated. 3. Grade state/outcome first; grade final text second. 4. Store transcripts for every trial. 5. Run multiple trials and report both capability and reliability metrics. 6. Keep a separate regression suite from exploratory capability evals. 7. Sample transcripts weekly, especially after score changes. 8. Treat evals like product infrastructure with owners, maintenance, and versioning.
Main caveat
The article is strongest on methodology, not on a universal implementation recipe. Teams still need to decide what state matters, how much nondeterminism is acceptable, and where LLM judges are reliable enough. The hard part is not knowing that outcome checks are better; it is designing outcome checks that match real user value without overfitting to a brittle path.
Bottom line
The article reframes agent evals as systems tests. The unit under test is not just the model; it is the model plus harness, tools, memory, environment, and product assumptions. That is the right mental model for modern agent engineering.