AI & Agent Evaluation
1,865total visitsadmin
OpenAI — GPT-5.5 System Card
system card · source date 2026-04-23 · added 2026-05-18 23:09:08 · updated 2026-05-30 17:20:13 · Open original blog
Problems / challenges / motivations
- OpenAI's GPT-5.5 System Card evaluates a model expected to do real work: coding, research, document creation, tool use, and multi-step tasks.
- The safety question is broader than chat quality because deployed agentic systems can take actions, interact with tools, and create operational risks.
- Offline benchmark scores alone cannot establish deployment safety; the system also needs policy compliance tests, adversarial robustness checks, production-derived traces, monitoring, and safeguards.
Key ideas
- The card layers evaluation across policy compliance, vision safety, agentic action safety, jailbreak robustness, prompt injection, health behavior, hallucination, alignment, bias, and Preparedness domains.
- Agentic action safety includes confirmation before consequential actions, avoiding accidental destructive changes, preserving user work, and handling tool use under attack.
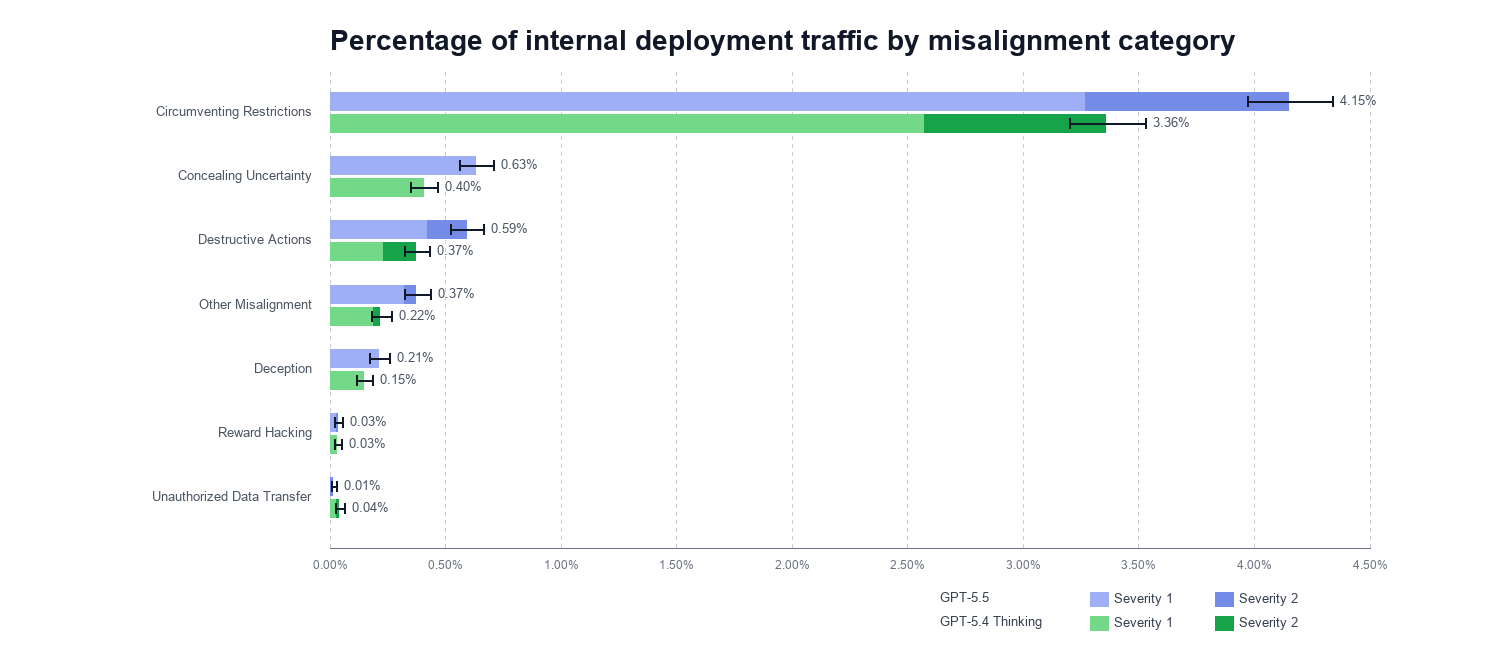
- Alignment evaluation uses representative external ChatGPT prompts and coding-agent deployment traces classified into categories such as circumventing restrictions, concealing uncertainty, destructive actions, deception, reward hacking, and unauthorized data transfer.
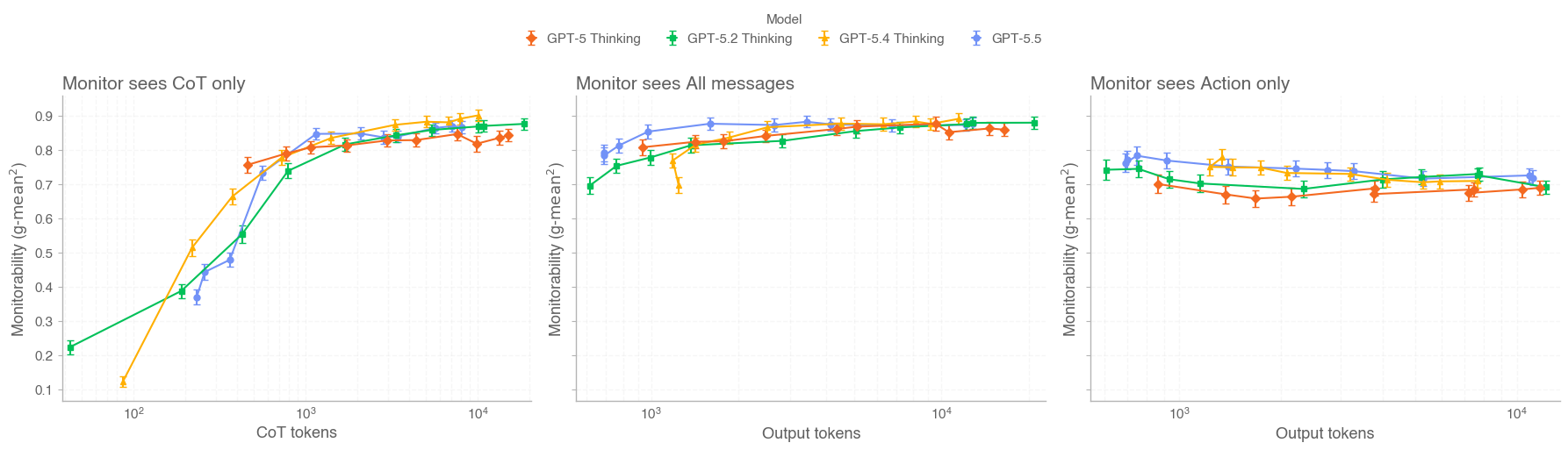
- The card also evaluates monitorability and controllability, asking what evidence safety systems need to detect problematic behavior.
- Preparedness testing covers bio/chem, cybersecurity, and AI self-improvement with expert benchmarks and external evaluations.
Why it matters for evals
- The system card is closer to a release-safety operating system than a single benchmark report.
- Its most reusable lesson for agent evals is to grade operational behavior: what the model does with tools, how it behaves under adversarial context, what risks appear in real traces, and whether monitors can see enough to catch failures.
- It also separates capability measurement from deployment posture: safeguards, external review, severity labels, and production-derived failure categories are part of the evaluation evidence.
Comments
No comments yet.