OpenReview survey · source date 2026-05-14 · added 2026-05-31 17:14:10 · updated 2026-05-31 22:24:31 · Open original blog
Agent Harness Engineering: A Survey
Source: OpenReview, published 2026-05-14. Project page: https://picrew.github.io/LLM-Harness/ OpenReview: https://openreview.net/forum?id=eONq7FdiHa
The paper's core claim is simple: for long-horizon LLM agents, the binding constraint is often not the base model alone. It is the execution harness around the model. A capable model can still fail if the harness gives it poor context, weak tools, no durable state, a brittle sandbox, inadequate observability, shallow verification, or unsafe permissions. Conversely, a fixed model can look substantially better when the harness improves planning, middleware, self-verification, environment setup, or failure recovery.
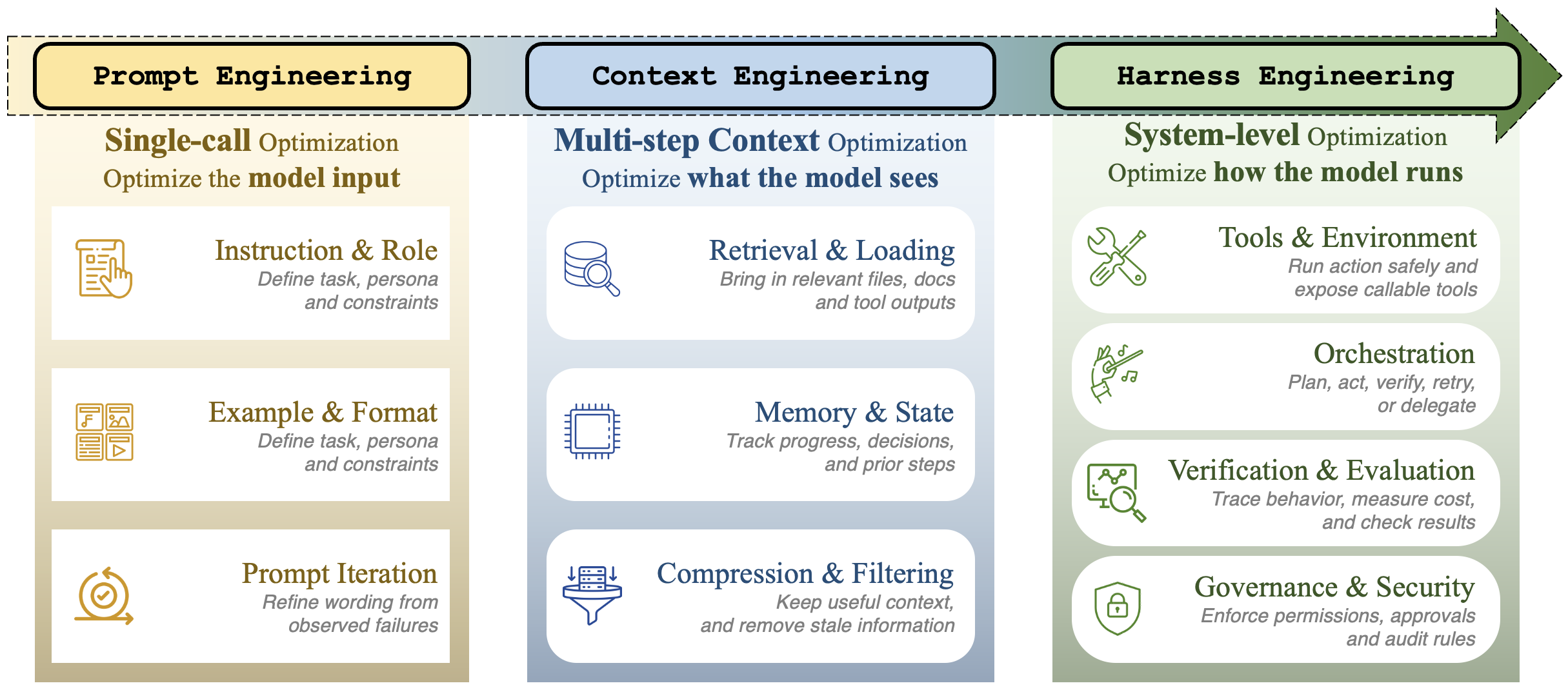
1. From prompt engineering to harness engineering
The survey frames agent engineering as a three-phase shift. Prompt engineering optimized the words sent to the model. Context engineering optimized what information the model sees at each step. Harness engineering treats the whole runtime as the engineering object: execution environments, tools, memory, orchestration, traces, verifiers, policies, budgets, and human handoffs.
This framing is useful because it explains why model-only comparisons become unstable for agents. A benchmark score can move because the model improved, but it can also move because the tool schema changed, context retrieval improved, a sandbox became less flaky, a verifier became stricter, or a retry loop was added. The paper calls attention to this model–harness coupling instead of treating it as implementation noise.
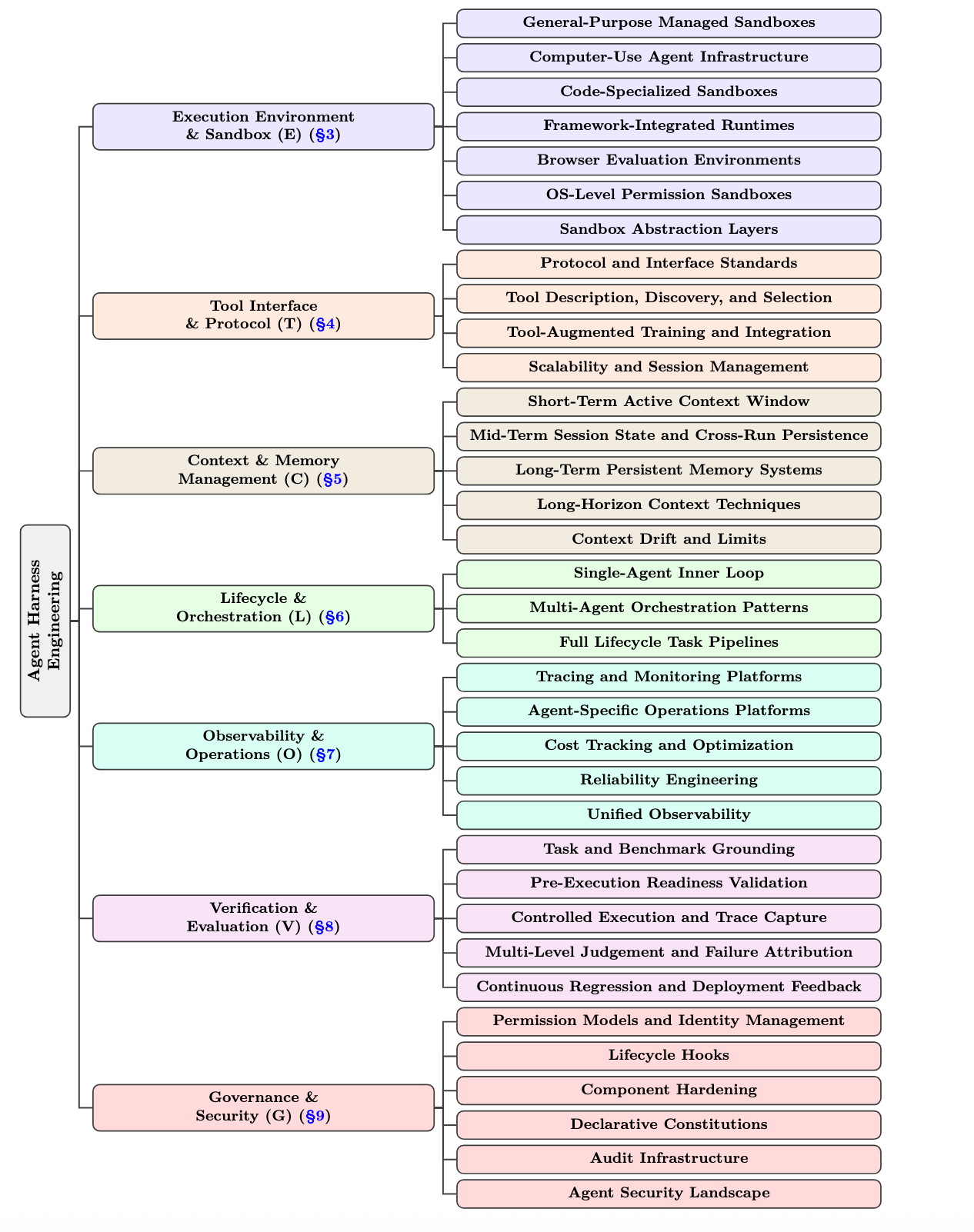
2. ETCLOVG: the seven-layer harness taxonomy
The paper's main taxonomy is ETCLOVG:
- E: Execution environment and sandbox
- T: Tool interface and protocol
- C: Context and memory management
- L: Lifecycle and orchestration
- O: Observability and operations
- V: Verification and evaluation
- G: Governance and security
The first four layers are the structural core. They decide where the agent runs, what it can call, what it sees, and how the loop is orchestrated. O, V, and G are the control plane. They decide whether the system is inspectable, measurable, and safe enough to operate.
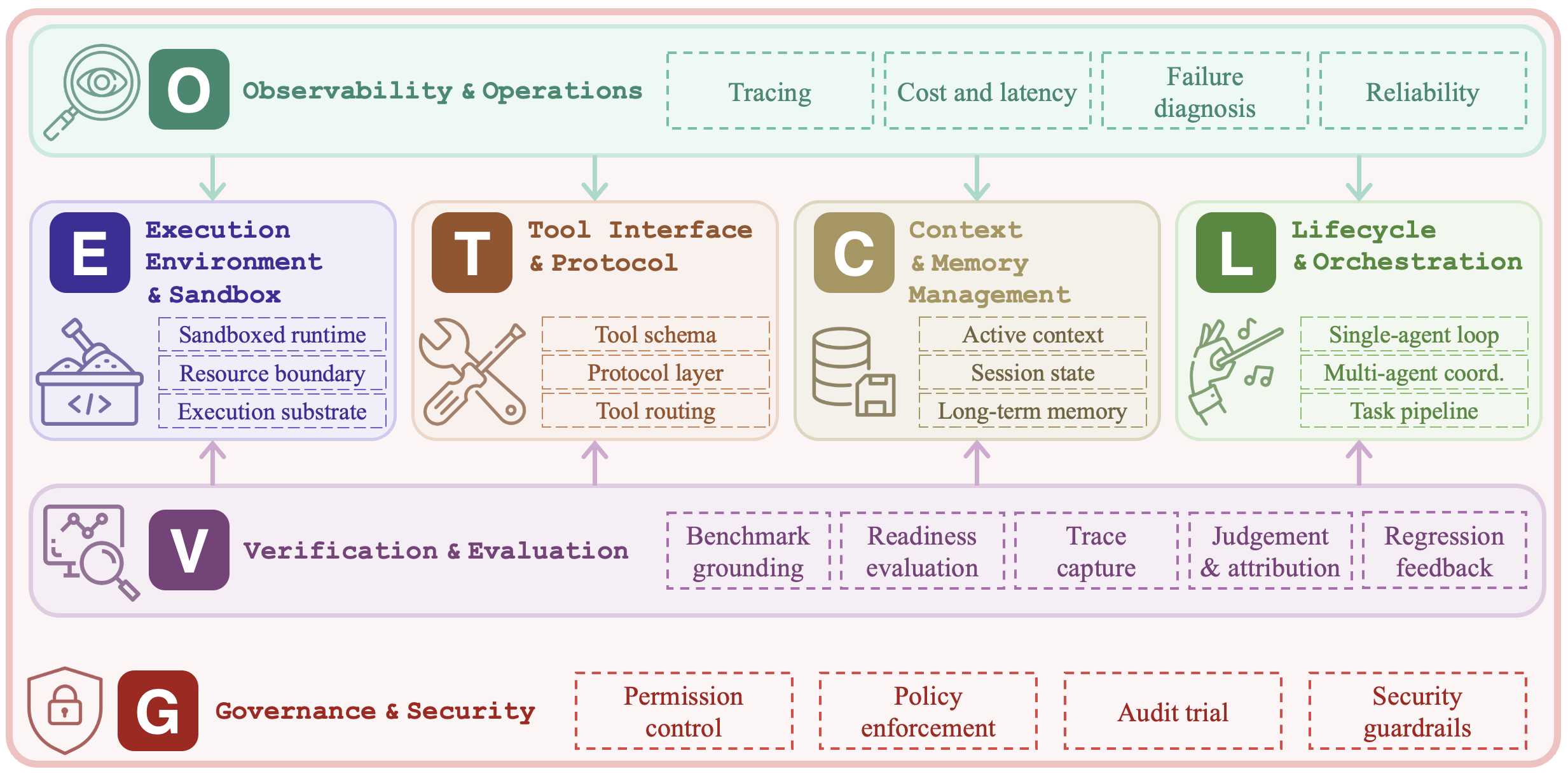
The important design choice is that Observability and Governance are not buried inside orchestration. The authors treat them as independent architectural concerns because production systems need separate tooling, ownership, and failure modes for tracing, monitoring, evaluation, permissions, safety, and audit.
3. What the taxonomy adds to agent evaluation
For AI eval, ETCLOVG is a checklist for hidden variables. If two agents are compared without disclosing their harnesses, the comparison may be under-specified. Did they have the same sandbox? The same tool set? The same retrieval policy? The same context budget? The same retry rules? The same verifier? The same permission gates? The same trace capture?
A strong agent-eval report should therefore describe the harness, not only the model and benchmark. The paper's practical implication is that every eval result should be treated as a measurement of a model–harness–environment system.
4. Section 7: Observability and Operations (O)
The user specifically asked to emphasize this. In the paper, Observability and Operations is Section 7 and the O component of ETCLOVG. It asks how agent behavior becomes inspectable, debuggable, and operable in production.
The paper separates several operational categories. Tracing and monitoring platforms record LLM calls, tool invocations, retrieval steps, context assembly, costs, latency, and failures. Agent-specific operations platforms add session tracking, agent identity, workflow views, tool policies, and trajectory visualization. Cost-tracking systems measure token spend, routing decisions, caching, latency, and quality-cost tradeoffs. Reliability engineering covers retries, checkpointing, recovery, durable event logs, and failure taxonomies.

The key idea is that observability is not passive logging. It is an operational control surface. A trace should help a team answer: what did the agent see, what did it decide, what did it call, what changed, what failed, what was retried, what did the verifier check, what did the human approve, and what did the run cost?
This is where many eval programs are still weak. They record final success but not enough evidence to explain success or failure. The paper highlights an observability-evaluation gap: many teams collect traces, fewer turn those traces into systematic offline evals and regression tests. The desired direction is trace-native evaluation, where production traces become regression cases and eval failures become monitoring signals.
For ai-eval.org, this section is especially important because it turns agent eval from leaderboard scoring into diagnosis. Useful observability metrics include trace completeness, failure attribution quality, replayability, operational cost, state visibility, alertability, and human-intervention burden.
5. Section 8: Verification and Evaluation (V)
Verification and Evaluation is Section 8 and the V component of ETCLOVG. Its main argument is that harness-aware evaluation should treat the score as a property of the model–harness pair. If the harness changes, the measurement changes.
The paper organizes evaluation as a five-stage task-to-feedback lifecycle:
1. Task and benchmark grounding: define the task, environment, tools, allowed actions, constraints, success criteria, and termination conditions. 2. Pre-execution readiness validation: check the sandbox, repository, browser, dependencies, tools, context state, permissions, budgets, and graders before the run starts. 3. Controlled execution and trace capture: run the agent while recording model outputs, tool calls, results, context snapshots, state changes, errors, retries, costs, and latency. 4. Multi-level judgement and failure attribution: evaluate the final outcome, the trajectory, and the evaluator itself, then localize the likely failure source. 5. Continuous regression and deployment feedback: convert benchmark failures and production incidents into regression suites for future harness changes.
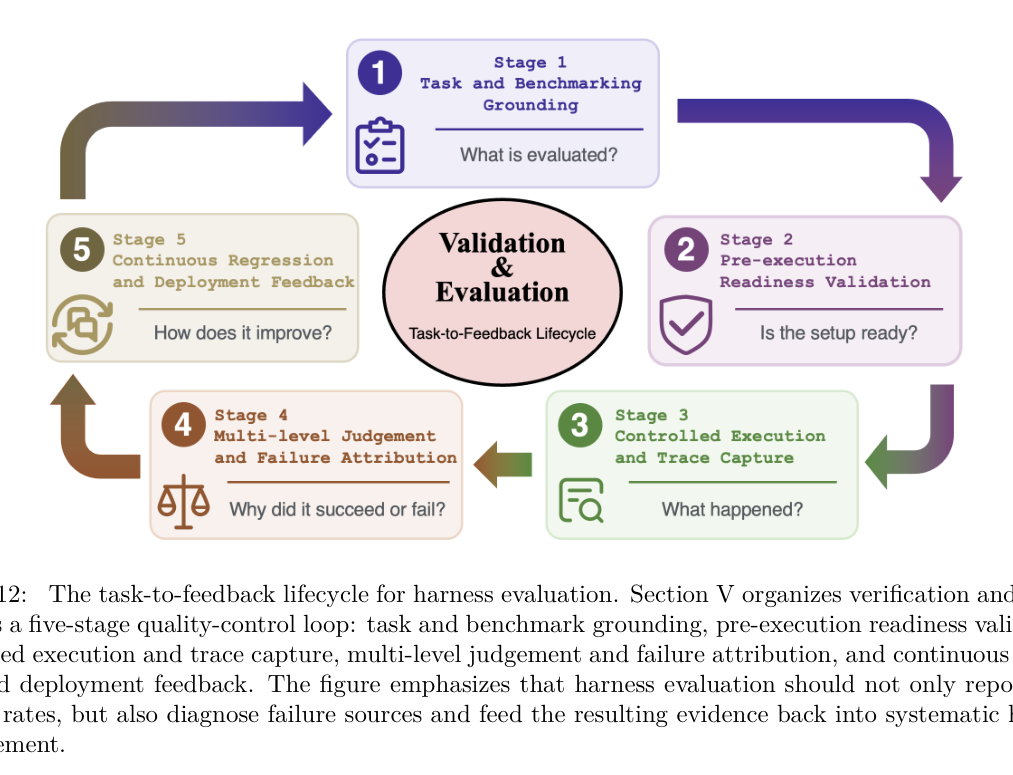
This lifecycle is the most directly eval-relevant figure in the paper. It says that an agent evaluation is not just a prompt, answer, and score. It is an execution episode with readiness checks, controlled rollout, trace capture, multiple judgement layers, failure attribution, and regression feedback.
The readiness stage is underrated. If the environment is broken, dependencies are stale, tool schemas drifted, memories leaked, permissions differ, or the grader is flaky, the eval result may not measure the model at all. Readiness metadata should include model configuration, tool registry, context policy, permission policy, budget, timeout, environment version, and evaluator version.
The judgement stage is also broader than final correctness. A run can achieve the final outcome while taking an unsafe, expensive, brittle, or unmaintainable path. Conversely, a failed run may contain valuable evidence about which harness component broke. The paper argues for outcome-level, trajectory-level, and evaluator-level judgement. That matches the direction agent evals need to go: score the result, inspect the path, and audit the grader.

6. The cross-layer synthesis: why harness changes are not local
One of the paper's useful engineering warnings is the harness coupling problem. Changes in one layer affect measurements in others. A new tool interface changes what context is needed. A new context policy changes how the lifecycle loop behaves. A new sandbox changes observability. A new verifier changes the reward signal. A new governance rule changes what counts as valid completion.
This creates three recurring tradeoffs.
First, the cost-quality-speed trilemma: richer context, stronger verification, better observability, and safer sandboxes improve reliability but cost more tokens, time, storage, and engineering effort.
Second, the capability-control tradeoff: giving the agent more tools, memory, autonomy, and execution access improves task coverage but increases blast radius and governance burden.
Third, the framework-to-platform shift: the field is moving from lightweight local abstractions toward durable platforms with sandboxes, identity, billing, observability, evaluation, governance, and human handoff.
7. Main caveats
The paper is a survey, not a controlled empirical benchmark. Its strongest contribution is taxonomy and synthesis, not a new measured result. Some corpus counts vary across the abstract, body, and project page, so the safest reading is that the authors map a large public corpus of agent-harness projects rather than relying on a single exact count.
Another caveat is that ETCLOVG is broad. Its value depends on using it operationally. The taxonomy should not become a label for everything around the model. It is useful when each layer is tied to concrete artifacts: sandbox images, tool schemas, context policies, orchestration state, trace schemas, evaluators, and governance hooks.
Bottom line
This paper is one of the clearest maps of agent harness engineering as a production discipline. For AI eval, its most important message is that agent performance is not model performance alone. It is model performance inside a harness.
The practical evaluation standard should therefore change. Report the harness. Capture the trace. Validate readiness. Judge the trajectory. Attribute failures. Test the evaluator. Feed production incidents back into regression suites. If Observability and Operations tell us what happened, and Verification and Evaluation tell us whether to trust it, then those two layers are the bridge from agent demos to reliable deployed systems.